

1、函数 mid
mid(提取谁,从哪开始,提取多长)
2、MOD 函数语法具有下列参数:
Number 必需。 要计算余数的被除数。
Divisor 必需。 除数。
-
3、RANDBETWEEN(bottom, top)RANDBETWEEN 函数语法具有下列参数:随机数
-
Bottom 必需。 RANDBETWEEN 将返回的最小整数。
-
Top 必需。 RANDBETWEEN 将返回的最大整数。


1、函数 mid
mid(提取谁,从哪开始,提取多长)
2、MOD 函数语法具有下列参数:
Number 必需。 要计算余数的被除数。
Divisor 必需。 除数。
3、RANDBETWEEN(bottom, top)RANDBETWEEN 函数语法具有下列参数:随机数
Bottom 必需。 RANDBETWEEN 将返回的最小整数。
Top 必需。 RANDBETWEEN 将返回的最大整数。
模型评估
一、算法评估
回归评估/分类评估
1、点估计;区间估计。先点后区间
2、 区间估计的准确率,可以视同位置信水平。
3、正态分布,平均值+-1.65倍标准差,90%样本;1.96标准差,95%样本;2.58标准差,99%样本。
标准:
1、无偏性。无数次计算的结果的均值,接近于jun zhi
一、估计量的求法:矩估计、最大似然、贝叶斯、最小二乘、em
1、最大似然,发生概率的连乘
卡放分布:多个标准正态分布的平方和。随着样本量的增大会收敛到正态分布。
t分布:小样本分析
f分布:
中心极限定理
1、统计量是一个样本函数,不含有任何未知参数。
2、密度函数:累计分布函数的一阶推导函数
1、高级筛选
标注不同两列数据中的交集值,然后复制到指定位置
countif(查找范围,目标值)
2、缺失值
a.缺失数做图表,有不连续出现。处理方式:右键图表-选择数据-隐藏到单元格和-选择即可。
b.时间的不连续(有日期存在无数据的情况),处理方式:设置坐标轴格式-文本格式坐标轴。
2、if函数嵌套方法
else方法(不成立部分),分步处理,步步处理else
3、公式-根据名称创建-名称,数据验证-序列,iindirect,处理步骤:
构造名称-大类列进行数据验证-确定小类-选择序列-用indirect函数
数据的类型、采集和展示
离散型数据
连续型数据(无限细分)
横截面数据
时间序列数据(时间属性)
面板数据(时间和空间)
excel 表格
1.定位
CTRL + A 全选
查找和选择 空值
2.选择性粘贴
粘贴值 快捷键 四步:
(CTRL+C、Ctrl+V、CTRL、V)
公式:按下F9会重新加载公式
例:randbetween(a,b)
3.查找替换
CTRL+H
这章明显讲得不如上面
正态分布大样本,T分布用于小样本
数据区域 alt+a
数据库:按照一定的数据结构来组织,储存和管理数据的仓库
企业数据面临的问题:存储大量数据,大量数据的检索和访问,保证数据信息的一致和完整,数据共享和安全。
数据库分类:关系型数据库,非关系醒数据库
表结构数据:以字段为基本的储存单位和计算单位
sql语言分类:
数据定义语DDL,数据操作语言DML,数据查询语言DQL
听不懂,兄弟。。。。
1.字符长短排序处理
构造辅助列 把问题转换为数字 量化 数据处理
思路 1先找到排序的方式 依靠字符的长度
2.确定函数 =len() 计算参数字符个数
2. 身份证号码 区分性别 15位
存储数据 需要空间的 永久性丢失 不可逆的
前面加个单引号 英文的 '
身份证号码倒数第二位 奇数男的
使用函数 = mid(位置,第几个开始,提取多长)
3.随机分组
a替换为 =a1 排序 点一个格子
rand 加上辅助列
4. 数据导入
Ctrl +Shitf 选中区域 进行操作
筛选出缺失值 进行批量处理
文本类型 (靠左)和数值类型
了解 函数 处理对象的 数据类型
数字 1. 数字本身
2.从1900年到该时间所对应的数值
快速填充 与分列 获取数据 
数据类型转换
socre *1 value() +0
show databases; show engines; use bufurulai; show tables; create table xiyouji( name text not null, age int not null, xihao text not null ); show tables; describe xiyouji; desc xiyouji; drop table xiyouji; alter table xiyouji rename wukongzhaun; desc wukongzhuan; alter table xiyouji change xihao xihao1 text; alter table xiyouji modify age int; alter table xiyouji modify age int8; alter table xiyouji add address text; desc xiyouji; alter table xiyouji modify address text first; alter table xiyouji modify address text after name; alter table xiyouji drop address;
1.选择性粘贴 主要对应函数 粘贴值
2.定位查找 格式
3.替换 名称变为公式 分组 将单元格名称
4.单元格格式匹配 区分数字
 分组
分组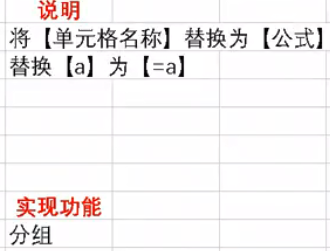
5.视图 冻结首行
6.辅助列 1.是用辅助计算,拆分公式 row 取到当前的行-1
row 取到当前的行-1
7.随机数
8.序号辅助列用来恢复原始顺序
9.工资表的表头重复 需求 加辅助列排序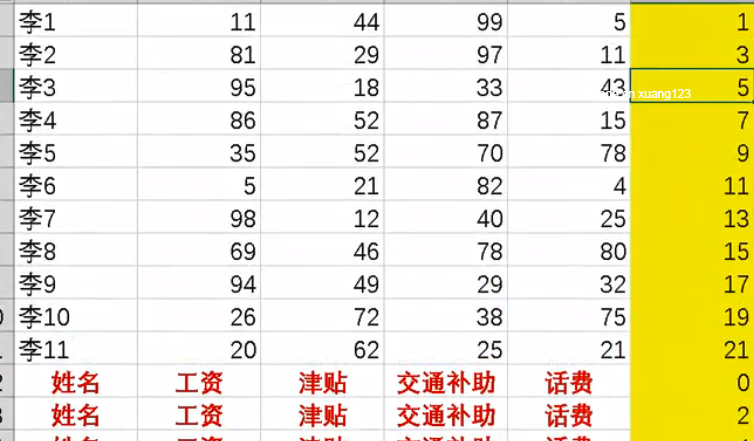 升序
升序
10.隔行设置格式处理
辅助列加上排序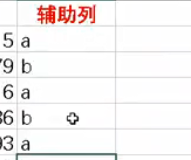
文本排序 算法 数据
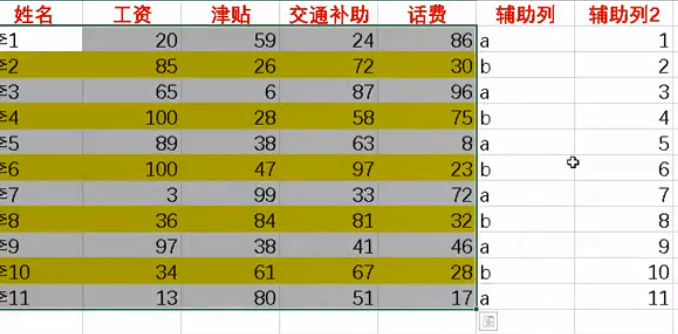
11.奇偶数操作
mod(分子,分母) 结果是余数 数据分类
批量操作
12.周末数据 跨行 处理 先判断 分类 
是星期几 返回几
13.大多数辅助列 用函数构造
14.删除空行 填充序列 列 终止值 步长
randbetween()
算法评估:
1、回归评估:平均绝对误差、平均平方误差
2、分类评估:
3、混淆矩阵:P=TP+FN表示世纪为正例的样本个数。ture\false表示分类器是否判断正确。
4、模型评价指标:准确率、错误率、灵敏度TP/P、特效度TN/N、精准度TP/(TP+FP)、找回度、其他。
5、F1 score 找回精确值:2除以两者分之一之和,
2、ROC曲线:曲线下的面积为AUC。
选择性粘贴
Ctrl C, Ctrl V, Ctrl, V





2")
