



“在数据分析中,并不是所有变量都能直接用来计算,比如像“红蓝”这样的分类变量。在利用和处理这种分类数据时,经常不能直接拿来使用。“
最近在球圈出了一个新闻:曼城俱乐部官方宣布签下埃及前锋马尔穆什!
英超联赛官方预告,2月23日曼城主场迎战利物浦时,埃及前锋萨拉赫与马尔穆什有望同场竞技。

曼城的新援马尔穆什将对阵利物浦的萨拉赫,这不仅是两位埃及国脚的巅峰较量,更是蓝色与红色的经典对决。
“红蓝对决”在体育比赛中通常指两支球队的经典对抗,而这些球队的代表色是“红色”和“蓝色”。

比如我们文章开篇新闻,利物浦(红色)、埃弗顿(蓝色)这两支球队都位于利物浦市,这场同城德比也是英超联赛中历史最悠久的对决之一。
在数据分析中,并不是所有变量都能直接用来计算,尤其是像“红蓝”这样的分类变量。
在利用和处理这种分类数据时,经常不能直接拿来使用,比如CDA数据分析师Level II 新教材《量化策略分析》第八章“线性回归”8.4.2小节中强调在进行线性回归建模时,如果放入分类变量,需要对多分类自变量进行哑变量变换,如下图(来自原书截图)。

那么为什么呢?
哑变量是个什么?
哑变量,也叫做虚拟变量(dummy variable),“dummy”这个词有“假的”、“虚拟的”、“哑的”等意思,国内的翻译五花八门,但它们指的其实完全一样的东西。
严格意义上,哑变量并不算一种变量类型(比如连续变量、分类变量),更准确地说,它是一种将多分类变量转换为二元变量的方法。我们刚次提到哑变量也叫做dummy variable,这个“虚拟”到底体现在哪呢?
假设我们有一个数据集,其中有一个列表示颜色,这列的值可能是“红色”、“蓝色”或者“绿色”。
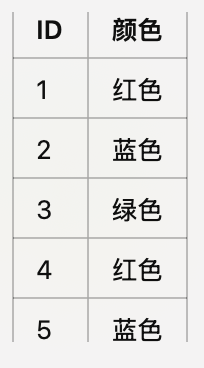
在这里“颜色”这个变量很明显是多分类变量(颜色有多个选项),我们要让计算机能够理解这些不同颜色的信息,所以需要将这些“红色”、“蓝色”、“绿色”转换为计算机能识别的0和1这种二分变量。
如何构建呢,如下,把每个颜色对应一个独立的列,并且每一行标明该颜色是否出现。
变成虚拟变量后的数据:
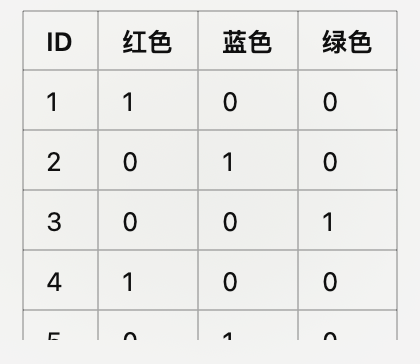
这就是“虚拟”的意思!我们把每个颜色的类别通过0和1表示出来——1表示该颜色出现,0表示没有出现。这样,原本复杂的颜色信息就变得简单直白,通过这种方式,虚拟变量让我们将分类变量转化为数值型数据,便于后续的数据分析和机器学习模型使用。
为什么需要哑变量?
回归分析的基础:线性
哑变量这种技术我们经常在回归分析中看到,如上文的教材线性回归那章节,回归分析主要探讨自变量X和因变量Y的关系,如下是其数学表示:
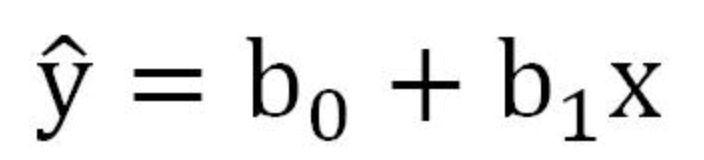
无论线性回还是logistic回归都要求x与y或者y的转换存在着线性关系。
通过数学表示,我们知道X对因变量Y的影响,可以用回归系数b1表示。
这种影响可以解释为:X每增加一个单位,Y平均增加b1的量,比如X是收入,Y是支出,那么X每增加1元的收入,支出将变化b1。这样的解释要求X与Y有线性关系。
这意味着X无论是10000元还是20000元,增加1个单位的情况下,支出的变化(增加)的幅度都一致,不然b1不代表X是10000时对支出的影响,也不代表X是2000时对Y的影响。
无序多分类自变量加入回归分析
但令人头痛的是:无序多分类自变量与因变量Y之间不存在线性关系。
比如下面这个例子:
有个研究者想要分析四种不同类型社区(用0、1、2、3表示)中的SO2(即二氧化
硫)浓度,看看社区类型是否与SO2水平有关,或者说,不同类型的社区SO2水平是否有差异。
在这个例子中,SO2水平是我们想要分析的因变量(也就是要研究的结果),而社区类型是自变量(也就是我们用来解释或预测结果的因素)。因为社区类型是一个分类数据,我们可以使用线性模型来进行分析。
下图中,黑色圆点代表每个社区类型的数据点。蓝色回归线表示线性回归拟合的结果,展示了社区类型和SO2水平之间的关系。
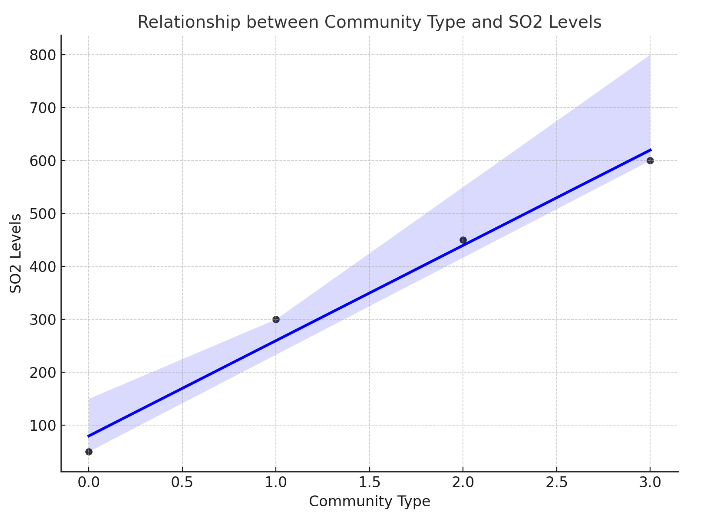
假如,我们把这个线性回归的模型计算出来了,其斜率是200,这意味着随着社区类型从0到3变化,SO2水平是线性增加的,每次变化的幅度(斜率)是200。换句话说,从社区类型0变到1,SO2水平增加200。从社区类型1变到2,SO2水平增加200。 从社区类型2变到3,SO2水平增加200。
但是,我们从图上发现并且完全如此,比如从1到2的变化增幅更大,从2到3增加的幅度没有那么明显。也就是说200的变化增幅是平均值。因此,无序多分类变量不能直接纳入回归进行分析。
如何构建哑变量,分析应用时注意什么
我们想要研究的是不同的社区类型对于空气中的SO2的影响,其实这里就隐含着我们需要有参照物,在解释分类变量的影响和结果时,必须要有参照物,比如我们经常看到新闻:60岁以上的群体糖尿病发病率更高,这意味着是与“60岁以下人群”进行对比。如果没有参照组,单单提到“60%”这个数字,无法判断它是高还是低。
因此如果多分类变量有k个类别,则可以转化为k-1个二分变量。如变量x为赋值1、2、3、4的四分类变量,就可以转换为3个赋值为0和1的二分类变量,然后这些变量跟剩下的作为参照。
通过这种虚拟变换,就可以把原来一个系数变成多个系数,从而解决了分类变量回归系数无法取平均值的棘手问题。这在非线性关系的模型中,特别重要。
那么如何在软件中实现哑变量的变换呢?目前大多数软件都可以实现,这里用python加以演示。
函数介绍
pandas 中可以利用 get_dummies() 函数进行哑变量变换。
pd.get_dummies(data, # 输入的数据框
prefix=None, # 列名的前缀
prefix_sep='_', # 分割符
dummy_na=False, # 增加一列空缺值
columns=None, # 指定要实现转换的列名
sparse=False,
drop_first=False, # 删除第一个类别值
dtype=None)
下面来看看这个函数如何使用进行数据转换。
代码实操
假如我们有一个数据集:
import pandas as pd
import numpy as np
s = pd.Series(list('abca'))
pd.get_dummies(s)

通过prefix='' 参数设置编码后的变量名,默认为:原始列名_取值。
df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'],
'C': [1, 2, 3]})
pd.get_dummies(df)
pd.get_dummies(df, prefix=['col1', 'col2'])
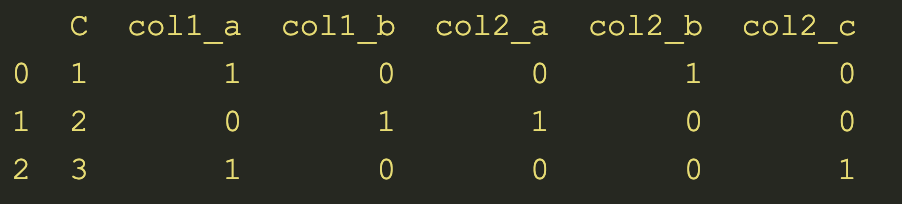
#drop_first 参数删除第一个类别,避免多重共线性。
pd.get_dummies(pd.Series(list('abcaa')))
pd.get_dummies(pd.Series(list('abcaa')), drop_first=True) # 删掉第一个
# 设置类型
pd.get_dummies(pd.Series(list('abc')), dtype=float)
# 合并至原始数据
df = df.join(pd.get_dummies(df.A))
pd.get_dummies(df, columns=['A'])
这样我们就把原本的多分类变量转换成了哑变量的表示。
- 还没有人评论,欢迎说说您的想法!


