



“ 常见的连续变量降维分为主成分分析、因子分析和变量聚类等方法。另外分类变量的降维则使用概化处理。”
在CDA数据分析师Level II新教材《量化策略分析》第六章市场调研与数据预处理中有这样一个知识点,如下图。

概化处理这个词你可能听的比较少,那么这项技术是如何实施,又为何需要呢?本文来带你详细学习。
为什么概化如此重要
在当今数据科学和人工智能的浪潮下,我们需要处理海量且复杂的数据。这些数据不仅包含连续变量,也包含分类变量,甚至是非结构化的数据。面对如此庞杂的信息,如何让机器学习模型更高效地从数据中学习,并在各种场景下保持稳健性?
其中有一种手段就是官网教材给出的技术-概化处理,针对分类型数据的简化技术。
概化处理的目标主要解决的是单变量数据问题中分类变量含有稀有水平或错误值问题。

数据如何概化处理
概化处理是数据预处理的一项重要技术,尤其在处理复杂数据时能够有效提高模型的稳定性与准确性。它通过简化数据的层级结构或合并数据中的不必要细节,帮助我们构建更高效的模型。接下来,我将详细解释三种常见的概化处理方法:简单合并、基于事实合并和基于算法的合并。

简单合并
简单合并是最基础、最直观的一种概化处理方法。它的核心思想是将原始数据中的一些类别或区间直接合并成较大类别。合并的原则可以非常简单,通常是根据某些相似性或可操作性来决定哪些类别或区间可以合并。要求合并后要求大类样本占比≥5%,且样本量不少于50个。
使用场景:
• 当数据集中某些类别的占比极小,可能会影响模型的稳定性时,直接进行合并。
• 例如,在用户分类、产品类别分析中,某些低频类别可以合并为“其他”类别,以减少类别数量,提高分析效率。
典型例子如: 地理位置可能包含很多小区域(比如城市或县区),通过简单合并,可以将小区域归类为更大的区域(例如,省份级别),来减少分析时的复杂性。
这种方法简单易操作,常用于数据初步预处理阶段,特别是在面对分类变量数量较多时。适用于那些类别间差异不大且合并后不会影响分析结果的情况。
根据事实合并
这种合并的主要思想是先计算每个类别的P值(p-value,指统计显著性指标)以及Logit值(对数几率),然后按P值大小进行排序,合并相近类别。
目的是尽量将样本量较小的类别合并到样本量较大的类别,保证合并后的分组仍具有统计意义,并且样本数仍然满足大于5%且不少于50个的要求。
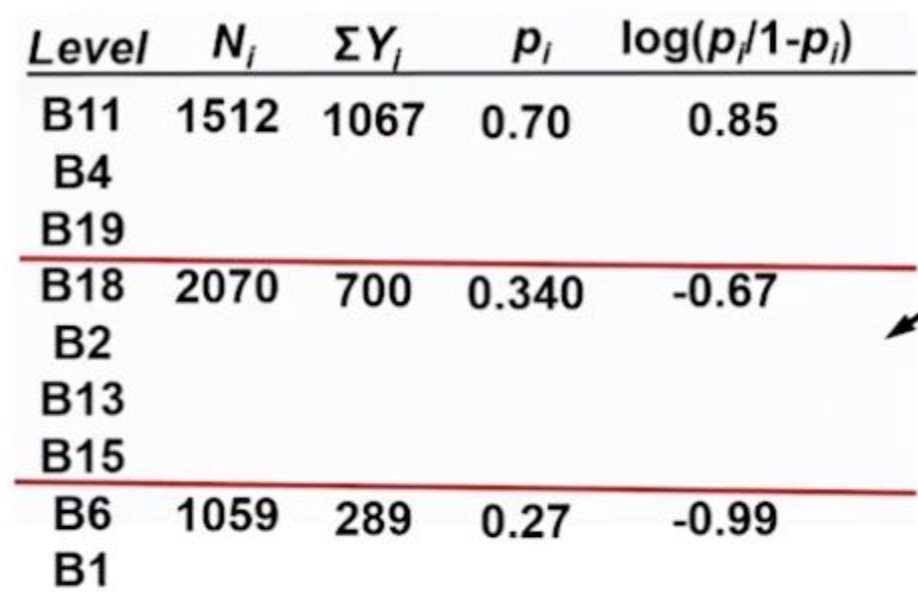
如图:• B11、B4、B19 被合并,它们的 Logit 值计算后为 0.85,表示这一组的特征较为一致。
• B18、B2、B13、B15 组合在一起,这一组的 Logit 值为 -0.67。
• B6 及其他类别 在另一个组合中,Logit 值为 -0.99。
在这里Logit 值是通过log(p / (1 - p)) 计算得出的,它用于衡量一个类别的事件发生概率。在极端情况下,某些类别可能会导致 Logit 值无法计算(如 p 值为 0 或 1),因此 P 值的适用性更广,可用于决定如何合并类别。
这种方法适用于信用评分建模、医疗风险评估等对数据精度要求较高的领域。
基于算法的合并
最后一种方法是基于算法的合并,该方法常与分箱方法结合使用,分箱方法是用于常用的消除异常值、离群值、极端值的做法。分箱算法包括对连续型变量进行等距等频分箱、也包括对分类变量进行合并。
基于算法的合并,常采用机器学习或统计算法自动决定如何合并类别,常见的方法包括:
• 卡方分箱法(ChiMerge):基于卡方检验,计算不同类别的显著性差异,并合并P值接近的类别。
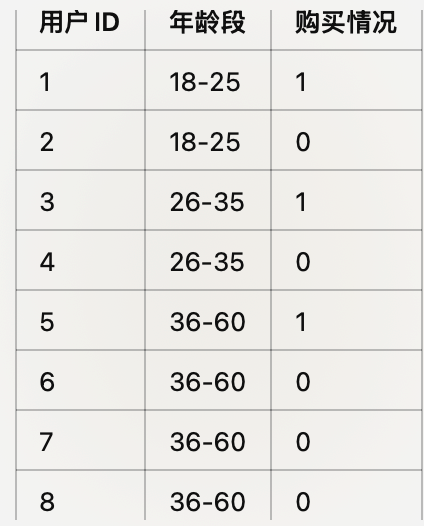
比如我们有一个关于用户购买某商品的数据集,记录了不同年龄段用户的购买情况(1表示购买,0表示未购买)。

首先,卡方分箱法会对不同类别之间的频次进行卡方检验。对于上述数据,假设年龄段为“18-25”,“26-35”,“36-45”和“46-60”四个类别,卡方检验将计算这些类别与“购买情况”之间的关系。
根据卡方统计量,计算每个类别与目标变量(购买情况)之间的P值。P值较低表示这些类别与目标变量之间的关系显著。
通过排序P值,卡方分箱法会合并P值接近且不显著的类别。在我们的例子中,可能会发现“36-45”与“46-60”这两个年龄段的P值较高,差异不显著,因而可以合并为一个新的年龄段(比如“36-60”)。
合并后的数据:
卡方分箱法有效地合并了差异不显著的类别,减少了数据维度,同时保持了重要的统计信息。
• 决策树分箱法(Decision Tree Binning):
决策树分箱法通过决策树模型自动选择最佳分箱方式。它通过构建一个决策树来判断如何将连续变量划分为多个区间,从而使得每个区间内的数据样本具有较高的纯度(即在目标变量上具有较大的一致性)。
在决策树分箱法中,选择分箱点的核心目标是最大化目标变量的纯度,即让每个分箱(区间)中的数据点在目标变量(如贷款批准=1或0)上尽可能一致。通常使用 信息增益(Information Gain) 或 基尼指数(Gini Index) 来衡量纯度,并决定最佳分箱点。
如下演示基于信息增益的最优分割:

信息增益基于 熵(Entropy) 的减少量来衡量纯度。熵越小,纯度越高。
比如我们有以下贷款数据:

- 计算未分箱前的熵:
• 总共有 7 个客户,其中 3 个贷款批准(1),4 个贷款未批准(0)。
• 计算整体熵:

- 计算以 收入=50K 为分箱点后的加权熵:
• 左侧(收入 ≤ 50K):客户(1,2,5)→ 贷款批准(1,1,0)
• 右侧(收入 > 50K):客户(3,4,6,7)→ 贷款批准(0,1,0,0)

如果 50K 的信息增益是最大值,则 50K 作为最佳分箱点。
决策树分箱方法适用于连续变量,通过决策树模型自动选择最佳的分箱点,确保每个区间内的数据具有较高的一致性。
这种通过算法自动优化类别合并,避免主观决定可能带来的误差。适用于大规模数据处理,特别是当类别众多且类别间关系复杂时。
- 还没有人评论,欢迎说说您的想法!


