


“分箱方法是通过考察数据的“近邻”来光滑有序数据的值,使有序值分布到一些桶或箱中。通常分为两种方法,分别是等深分箱和等宽分箱。“--摘自CDA数据分析师2级教材第六章《市场调研与数据预处理》。

最近在做一个数据分析项目时,遇到了一个头疼的问题。
从数据噪声,到分箱方法
年前,我们手头有一组银行用户的交易数据,目标是预测哪些用户更可能逾期还款。数据看起来很丰富,几十万条记录,数十个特征,涵盖了用户的年龄、收入、信用评分、交易金额等信息。
但建模后发现:
数据太“杂”了:信用评分从 300 到 850,年龄从 18 到 80,交易金额跨度更是夸张,从几块钱到上百万。这些数值型特征的分布极不均匀,导致模型难以学习模式。
过拟合风险:某些变量对模型的影响过大,比如年龄,模型可能会误以为“38 岁比 37 岁更容易逾期”,但实际上,人的信用风险不会因为生日多过一天而发生明显变化。
极端值的影响:有些用户的收入远远超出普通人群范围,而部分用户的消费异常波动,使得数据分布严重偏斜。如何让数据更加易用?
分箱方法:让数据更加平滑有序
数据分箱的核心思想是:考察数据的“近邻”关系,把连续数据划分为多个区间(桶或箱),让模型更容易理解模式,同时减少噪声对结果的干扰。
分箱可以让数据变得更加稳定,同时提升模型的泛化能力。特别是在信用评分、市场分析、天气预测等领域,分箱是一个不可或缺的工具。
目前,最常见的分箱方法主要有两种:
-
等深分箱(Equal Frequency Binning)
-
等宽分箱(Equal Width Binning)
等深分箱:每个箱子装的人数一样多
等深分箱,顾名思义,就是让每个分箱中的样本数量相等,也就是说,每个区间包含的数据点数量相似,而区间的宽度可能不均匀。
举个例子
假设我们有一组用户的月收入数据(单位:元):
[3000, 5000, 7000, 10000, 12000, 15000, 20000, 30000, 50000, 80000]
如果我们想把这些收入数据分成 3 个等深分箱,每个分箱 3~4 个样本,可能得到如下分组:
• 第一箱(低收入群体): 3000, 5000, 7000
• 第二箱(中等收入群体): 10000, 12000, 15000, 20000
• 第三箱(高收入群体): 30000, 50000, 80000
等深分箱的特点:
对:适用于数据分布不均匀的情况,例如信用评分或电商用户消费数据。
对:避免某些分箱内样本过多、另一些分箱内样本过少的问题,使数据分布更均衡。
对:适用于极端值较多的数据集,避免个别值对模型产生不合理的影响。
错:但由于分箱的宽度不固定,可能导致某些区间的数值跨度过大,影响模型的可解释性。
等宽分箱:每个箱子的宽度一样大
等宽分箱,就是让每个分箱的取值范围相等,这样每个箱子的跨度是固定的,但每个分箱中的数据量可能不同。
用同样的收入数据,我们尝试等宽分箱
• 数据范围:最小值 3000,最大值 80000
• 设定 3 个等宽分箱,计算宽度:
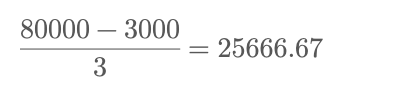
取整数 25000 作为分箱区间。
分箱结果如下:
• 第一箱(低收入群体)(3000~28000): 3000, 5000, 7000, 10000, 12000, 15000, 20000
• 第二箱(中等收入群体)(28000~53000): 30000, 50000
• 第三箱(高收入群体)(53000~80000): 80000
等宽分箱的特点:
对:计算简单,容易理解,适用于数据分布均匀的情况。
对:适合温度、时间、地理位置等变量,保持数值范围的等距划分。
错:如果数据分布不均匀,可能会导致某些分箱过密,而某些分箱过稀疏,影响数据的代表性。
等深 vs. 等宽:如何选择?
|
方法 |
优点 |
缺点 |
适用场景 |
|
等深分箱 |
每个分箱样本数均匀,避免数据偏斜影响 |
区间宽度不均匀 |
适用于信用评分、电商用户行为分析 |
|
等宽分箱 |
计算简单,易于解释 |
数据不均匀时可能导致某些区间过密或过稀疏 |
适用于温度、时间、地理位置等变量 |
一句话总结:
• 数据分布均匀 → 选 等宽分箱,比如天气数据。
• 数据分布不均匀 → 选 等深分箱,比如收入、信用评分。
数据分箱:模型的稳定器
分箱不仅仅是为了让数据更整洁,它还有着更深远的影响,比如:
在 信用风险评估 中,合理的分箱可以让评分模型更加稳定,避免过拟合。
在 医疗数据分析 中,分箱可以帮助医生更好地判断不同年龄段的健康风险。
在 市场营销 中,分箱可以让商家更精准地划分客户群体,进行个性化推荐。
回到文章开头,我们的金融风控项目最终选择了等深分箱来处理信用评分数据,让模型在不同人群中都能保持良好的预测能力。分箱就像是一个过滤器,让数据更加清晰有序,让模型能够专注于真正重要的信息。
- 还没有人评论,欢迎说说您的想法!


