



“ 三种方法对比来看,非对称变量在聚类分析中选用百分位秩和 Tukey 正态分布
比较多,在回归分析中取对数比较多。因为商业上的聚类模型关心的是客户的排序
情况,回归模型关心的是其具有经济学意义,自然对数表达的是百分比的变化。”
---摘自CDA数据分析师Level II教材6.3.6《连续变量分布形态转换》。

最近在处理一组经济数据时,我们发现模型的表现非常不稳定。经过排查,问题出在数据的分布形态上。很多社会经济变量,比如收入、房价、交易额,都存在右偏问题,导致传统的建模方法难以拟合。
这让我想到了数据科学中的一个重要环节——连续变量分布形态转换。当数据分布不均匀时,我们可以使用不同的转换方法,使数据更符合建模需求。但在回归分析和聚类分析中,我们应该如何选择合适的方法呢?
为什么要转换数据的分布形态?
在机器学习和统计建模中,许多算法都有特定的假设。例如,线性回归假设残差服从正态分布,而某些聚类算法假设特征空间中的样本分布均匀。但在现实中,许多变量的分布是偏态的,尤其是在金融、经济和商业数据中,比如:
- 收入水平:大部分人收入集中在中低水平,极少数人收入极高 → 右偏分布
- 公司利润:大多数公司盈利有限,少数公司盈利巨大 → 长尾分布
- 房价:大多数房价较低,部分豪宅价格极高 → 幂律分布

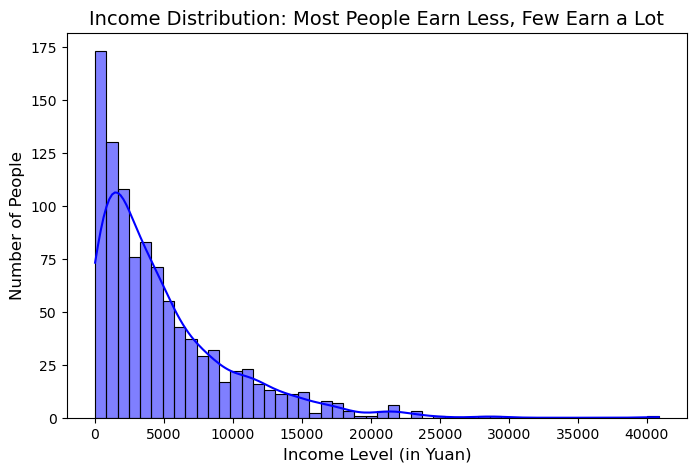
如果不进行适当的转换,数据的偏态性可能会导致模型表现不稳定,甚至误导分析结果。
数据偏态带来的问题
• 影响回归分析的稳定性:如果目标变量是右偏的,那么回归模型可能会受到极端值的干扰,导致预测不准确。
• 影响聚类结果:如果特征值分布不均匀,聚类算法可能会被数据的某些部分主导,会形成一些极端的聚类,因此,合理的分布转换至关重要。那么,如何选择合适的方法呢?
三种常见的分布转换方法
方法 1:百分位秩转换(Percentile Rank Transformation)
核心思路:
• 将变量从小到大排序,赋予序列号,并除以样本总量,使变量值落入0,100的区间内。
• 适用于聚类分析,因为聚类模型更关心数据的相对顺序,而不是绝对数值。
百分位秩用于衡量一个数据点在整个数据集中的相对位置。其计算公式如下:
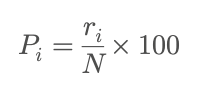
其中:
• P_i 是第 i 个数据点的 百分位秩(Percentile Rank),值域为 **[0, 100]**。
• r_i 是该数据点在有序数据集中的 排名(Rank),即从小到大排序后的序号。
• N 是 总样本数。
示例:
假设我们有 10 个人的收入数据(单位:万元):
[3, 5, 7, 10, 12, 15, 20, 30, 50, 80]
我们先对数据进行升序排列,并计算每个数据的百分位秩:

所以,对于一个新的数据点,如果它的百分位秩是 70%,这意味着70% 的数据点小于或等于它。
适用于:
• 聚类分析(因为聚类关注的是数据的相对顺序)。
• 排序和排名类问题(如信用评分分段)。
方法 2:Tukey 正态转换(Tukey Transformation to Normality)
核心思路:
• 先进行百分位秩转换,然后映射到标准正态分布,确保数据呈对称分布,适用于统计分析。
转换公式
假设数据的百分位秩是 P_i ,那么可以使用 标准正态分布的逆累积分布函数(Inverse CDF 或 Percent-Point Function) 来转换为 Z 分数。
Z 分数的计算公式是:
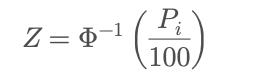
其中:
• Z 是标准正态分布下的 Z 分数(也称为标准化值),
• Phi^{-1} 是正态分布的逆累积分布函数,
• P_i 是数据点的百分位秩。
示例:
如果我们将上面的百分位秩转换为标准正态值(Z 分数):

适用于:
• 需要假设变量服从正态分布的模型,如分类模型、聚类分析。
• 适用于数据分布严重偏态的情况。
方法 3:自然对数转换(Log Transformation)
核心思路:
• 对数变换可以拉近右偏数据,使其更加对称,特别适用于经济和金融数据。
数学公式:
A = ln(x)
如果仍然偏态,可以进一步使用二次对数:
A = ln(ln(x))
示例:
假设我们对上面的收入数据取自然对数:

适用于:
• 回归分析,尤其是经济学数据(如收入、利润)。
• 解释数据的百分比变化,如增长率。
回归 vs. 聚类:如何选择正确的方法?

数据分布的转换并不是万能的,但它可以有效改善建模效果。回归分析更适合使用对数转换,更关注数值的经济学意义;而聚类分析更适合百分位秩转换或 Tukey 变换,更注重排序。
- 还没有人评论,欢迎说说您的想法!


