


median:中位数
mean:平均数
mode:众数

median:中位数
mean:平均数
mode:众数
检查中心水平:
spss:
内限:最大最小值,不是数据的最大最小值「上分位点加上1.5倍的内分位距(IQR)」
外限:真的变量的最大最小值
OLAP:联机的数据处理的操作,数据本身架构形式的处理。
第一章 数据分析概述:
数据分析介于BI和AI之间。
多维分析:每一个样本可能涉及到的多种属性。
警报:把数据作为摄像头,来检测每个周期的数据变化。如果出现了异常数据,则要为我的检测者做报告。
训练集和测试集:通过训练得到一系列数据,但是需要测试、评估它是不是最好的。
过采样:取值过少,可能需要更多抽样方法
1、评估指标
精确度
召回率
f1 score
2、机器学习分类
有监督学习;分类任务-离散值;回归任务-连续值
无监督学习(不带标签的数据,让数据自己介绍自己):聚类任务;降维任务
半监督学习
强化学习,试错方式
看不懂。。。。。。
1、线性回归,用于处理截面数据。
1、相同或相似时间点的数据,截面数据。
2、中位数大于平均数,左偏分布。
右偏分布的最大值是平均数。
12.21 描述性统计分析
1、计量尺度。
a、名义测量(分类变量),数值代表符号,无顺序大小。频次/百分比/累计频次及累计百分比。
b、次序测量(顺序变量),有序分类,数字有高低。
c、连续变量测量(间距、比率)间距数值为相对,能加减,不可乘除。
四考察:
中心水平:均值;众数(出现次数最多);中位数,先排序后的中间值,数量为偶数时为[(n/2)+(n+1)/2]/2;四分位数,四等分后由中位数、上四分位数、下四分位数组成;平均数;加权平均数;几何平均数;
离散程度:异众比率(非众数比率);极差(最大-最小);四分位差(上分位数-下分位数);方差(本值与均值间的距离均值);
偏度:左偏(左边的变量线拖尾)、右偏(较普遍)
峰度:值高说明峰高。
2、统计图形:条形图;盒须图;玫瑰图
以上变量的量化水平,由低到高,低水平变量可以用于高水平统计,反之不行。
算法体系:
有监督学习:指对数据的若干特征与若干标签之间的关联性进行建模。
无监督学习:不带任何标签的数据特征进行建模;聚类、降维。
强化学习:
半监督学习
泛化能力:模型在未知数据集上的效果,在陌生数据集上表现优秀的能力称为泛化能力,我们追求的是模型的泛化能力。
训练误差:错分样本的比例
交差验证:K折交叉沿着
测试误差
交差验证
机器学习:
获取数据--获取一个任务--根据数据和算法进行学习--模型评估
模型效果
准确率、运算速度需要接近或超过人类,才有意义
OLAP分析问题不是统计模型
业务理解---企业认知
数据理解
数据准备(探索--修改(数据清洗)--建模--评估--抽样--探索)
数据建模
建模评估→业务理解
模型发布
OLAP是数据架构处理
维度——数据中的每一列
警报——监测异常数据,并警报
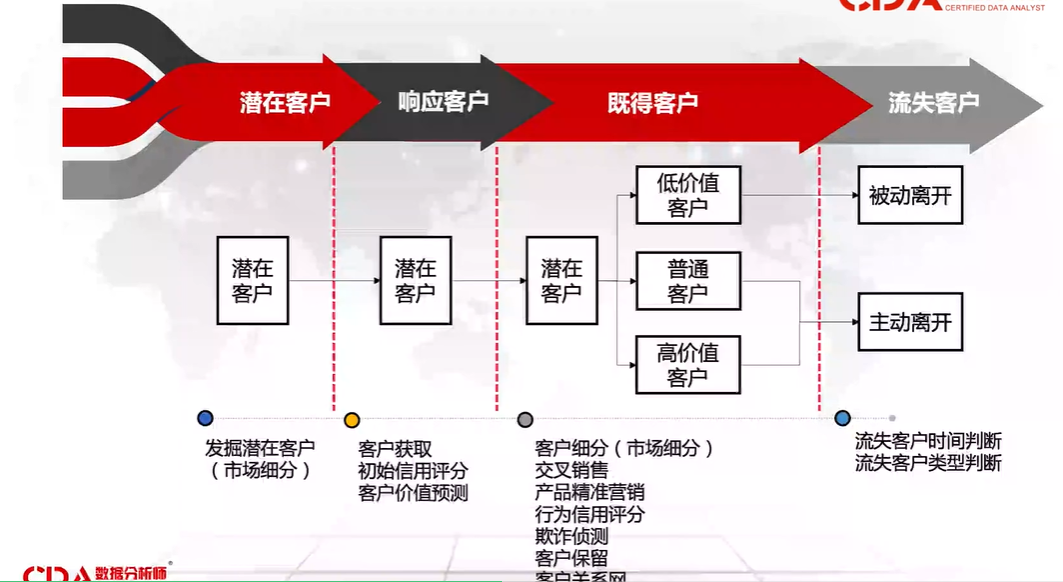
线性回归
线性回归基本假设
中心极限理论





