1. 随机试验

2. 随机事件
3. 随机变量

1. 随机试验
2. 随机事件
3. 随机变量

切比雪夫
1. 数据的计量尺度和具体的统计方法相关
名义测量-分类变量:数值谨代表某些分类或属性,不做高低,大小区分。如男女
次序测量-顺序变量:量化水平高于名义测量,具有一定的顺序性。如学历水平
连续变量测量-数值变量 (间距测量、比例测量)
间距测量:量化水平更高,其取值不再是类的编码,而是采用一定单位的实际测量值。可以进行加减运算,但不能进行乘除运算。
比例测量:最高级的测量等级。可以进行加减乘除,其0具有绝对意义
2 数据描述
分类变量:检查众数,百分比:
频次/频数、百分比、累积频次与累积百分比(仅对次序变量有意义)
顺序变量:众数,频次,百分比,百分比,累积
连续变量: 中心水平、离散程度、偏度和峰度
注意⚠️:分类变量、顺序变量、连续变量的量化水平是由低到高的,低水平变量的统计量可以用于高水平,反之则不一定
3 连续变量-中心水平:能代表“中心”概念的可选统计量有均值,中位数和众数
众数(数据量较大时有意义):出现次数最多的变量值,众数不是唯一的
中位数:排序后处于中间位置的值
样本量为奇数时,中位数为中间值
样本量为偶数是时,中位数为中间两值的均值,是一个计算值
四分位数:一组数据排序后,处于25%(下四分位数)和75%(上四分位数)位置处的数字
均值-算数平均数:样本平均数、总体平均数。
均值-加权平均数:样本加权平均,总体加权平均
均值-几何平均数:主要用于计算平均增长率,适用于比率数据的平均。
各个中心水平度量的比较:众数和中位数不易收到极端值的影响,平均数容易受到极端值影响。众数和中位数适合在非对称情况下使用。
4. 连续变量-离散程度:离散程度反映中心水平的代表性。
离散程度度量指标:

5. 连续变量-偏度:用来刻画偏态的程度
6. 连续变量-峰度:变量向两边拖尾的情况。正态分布峰度为0
7 统计图形
条形图
盒须图(箱线图):提供中位数,均值,上线分位点的信息
玫瑰图(南丁格尔玫瑰图)
1. 数据分析是一套分析流程,包括业务理解,数据采集,数据清洗,数据探索,数据可视化,数据建模,模型结果可视化,分析结果的业务应用等;它以探索数据内的有用信息为主要途径,以解决业务需求为最终目标。
2. 数据挖掘是一个跨学科的计算机科学分支,是一种计算过程;用人工智能,机器学习,统计学和数据库的交叉方法在相对较大型的数据集中发现模式
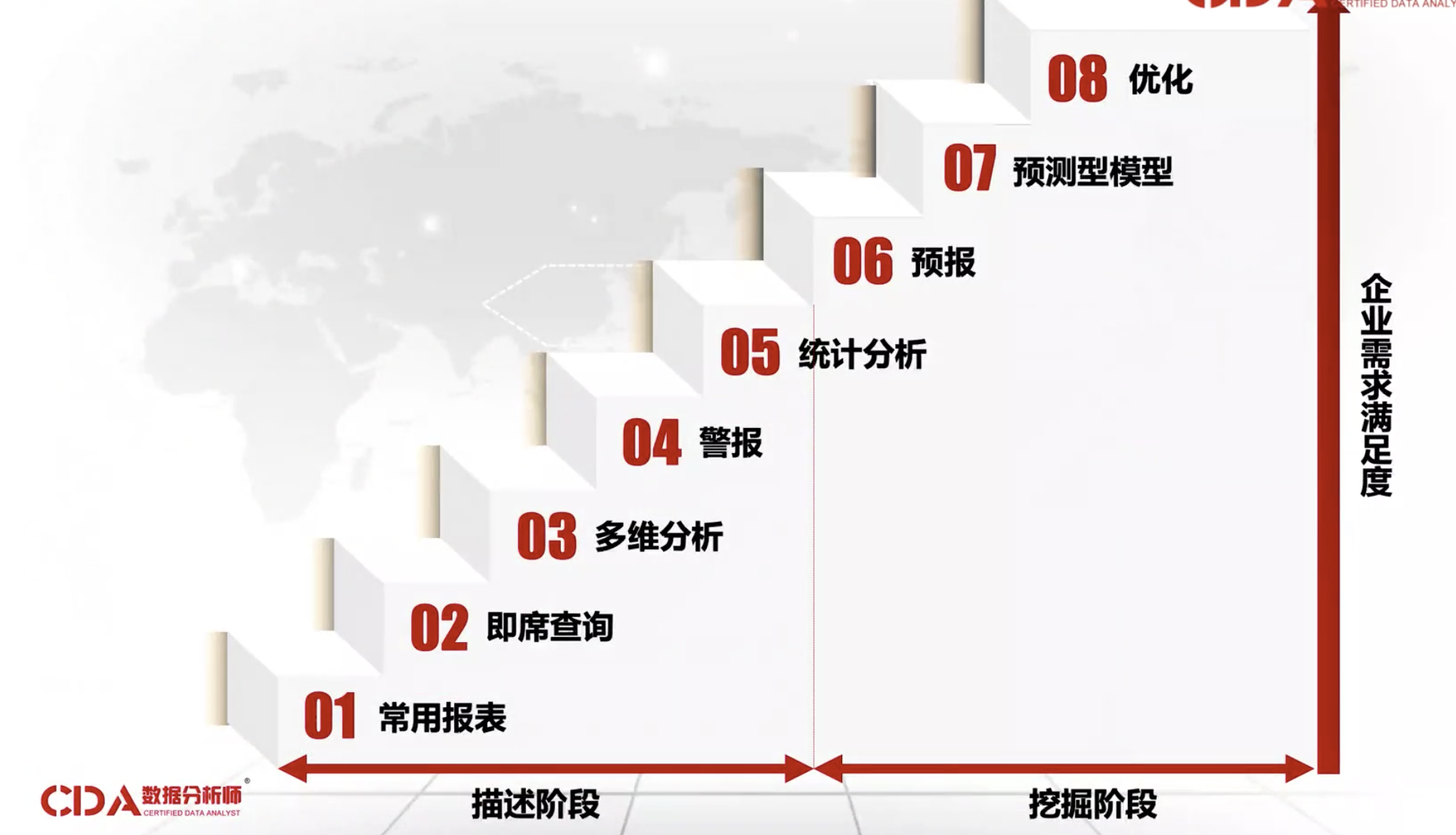
3. 数据分析的8个层次
4.小数据与大数据关系
小数据重抽样,基于样本推断总体
大数据重全体,偏向于机器学习,侧重效率和优化

5. 数据分析的意义
数据分析涉及到公司运营的方方面面,其中客户与市场的数据分析是重点
6. 客户生命周期与数据分析的关系
潜在:发掘潜在客户--如何找到潜在客户
响应:客户获取,初始信用评分,客户价值预测
既得:客户细分,精准营销,行为信用评分,客户保留。。。
流失:流失时间判断,流失类型判断
7. 数据挖掘方法论
CRISP-DM 方法论将数据挖掘项目生命周期分为6个阶段:业务理解,数据理解,数据准备,建模,模型评估和模型发布

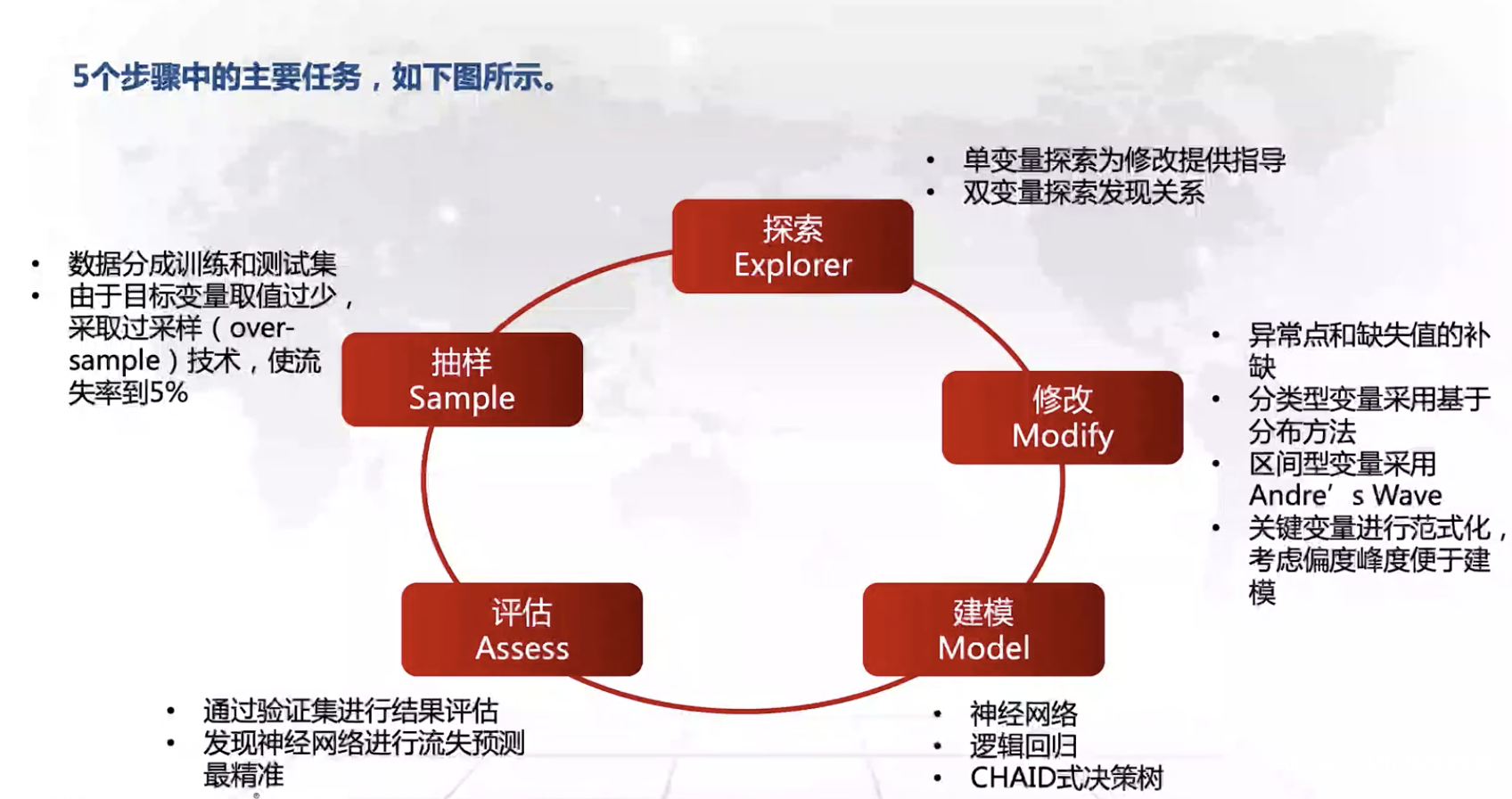
SEMMA方法论:数据挖掘项目实施的方法论,对CRISP方法论中的数据准备和建模环节进行了拓展。

挖掘阶段的任务